数据掩蔽(data masking)和数据混淆(data obfuscation)的区别
关键区别:数据掩蔽或数据混淆是指有助于隐藏私有数据的过程。它也被称为数据匿名化。因此,两者没有区别。这些过程有助于保护生产数据库中的敏感信息,以便可以轻松地将这些信息提供给测试团队等实体。
包括(“ad4th.php”);?>
数据掩蔽或数据混淆是指有助于隐藏私有数据的过程。它也被称为数据匿名化。因此,两者没有区别。这些过程有助于保护生产数据库中的敏感信息,以便可以轻松地将这些信息提供给测试团队等实体。

敏感数据的隐藏是一个重要的问题。因此,应用各种方法来隐藏这些信息。许多方法被用来隐藏信息。例如,可以生成新的数据或进行数据加密。洗牌是另一种方法,数据可以在一列中洗牌。
数据以一种看起来真实并且看起来一致的方式被屏蔽。数据掩蔽有助于保护敏感和个人数据,从而降低暴露的风险。值得一提的是,在这个过程中,数据的格式保持不变。但是,会对值进行更改。通过使用各种方法中的任何一种来改变数据。这些值以一种可以在以后进行更改或反向工程的方式进行更改。IBM、Informatica、Oracle等供应商在市场上提供了许多数据屏蔽产品。
包括(“ad3rd.php”);?>
在实际场景中,各种数据掩蔽方法的组合也适用于不同的数据字段。数据掩蔽还降低了潜在测试数据泄露的风险。它一般遵循敏感数据识别、监控、屏蔽数据和审计的步骤。数据掩蔽策略必须覆盖共享数据或有可能共享数据的所有领域。应屏蔽数据以减少外部和内部风险。必须根据需要选择适当的工具进行数据掩蔽或模糊处理。
数据掩蔽和模糊处理的比较:
|
| 数据屏蔽 | 数据混淆 |
| 意义 | 数据掩蔽是指帮助隐藏私有数据的过程。它也被称为数据匿名化。这些过程有助于保护生产数据库中的敏感信息,以便可以轻松地将这些信息提供给测试团队等实体。 | 它与数据屏蔽相同。因此,两者没有区别。 |
| 技术 | 随机替换–将要屏蔽的值替换为随机值。算法替换–特定字段使用特定算法生成。序列–生成数据序列选择性屏蔽–仅屏蔽特定部分。模糊–将随机方差添加到现有值表达式–自定义规则或表达式用于屏蔽复杂的字段。 | 与数据屏蔽相同 |
| 工具供应商 | IBM、Informatica、Oracle等 | IBM、Informatica、Oracle等。 |
- 发表于 2021-07-14 00:28
- 阅读 ( 541 )
- 分类:通用
你可能感兴趣的文章
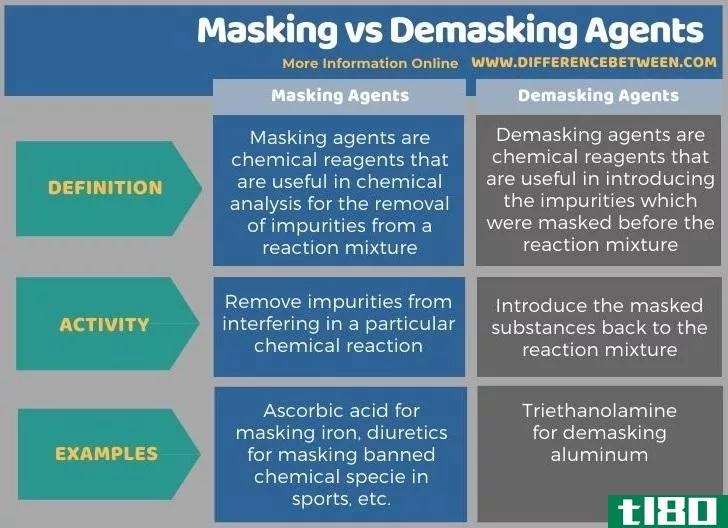
掩蔽(masking)和去污剂(demasking agents)的区别
掩蔽剂和去掩蔽剂之间的关键区别在于,掩蔽剂可用于螯合分析过程中来自化学物质的任何干扰,而去掩蔽剂可用于释放之前掩蔽的干扰。 掩蔽剂和去掩蔽剂在化学分析技术中是重要的,用于从反应混合物中去除和引入杂质...

数据仓库(data warehousing)和数据集市(data marts)的区别
数据仓库与数据集市 你应该先建立哪一个:数据仓库还是数据集市?这个问题最近一直困扰着IT经理。大多数供应商都会说,数据仓库很难做到,而且成本很高,因此不可取。他们说建立数据仓库需要很长时间。此外,他们还...

数据挖掘(data mining)和数据仓库(data warehousing)的区别
数据挖掘和数据仓库的主要区别在于,数据挖掘是从大量数据中识别模式的过程,而数据仓库是将来自多个数据源的数据集成到一个中心位置的过程。 数据挖掘是在大型数据集中发现模式的过程。它使用各种技术,如分类、回...

大数据(big data)和数据分析(data analytics)的区别
大数据与数据分析的主要区别在于,大数据是大量的复杂数据,而数据分析是对数据进行检查、转换和建模,以识别有用信息并支持决策的过程。 大数据是指海量的数据。这些数据可以是结构化的、非结构化的或半结构化的。...

主数据(master data)和交易数据(transaction data)的区别
主数据和事务数据的主要区别在于,主数据是表示与组织相关的人员、地点或事物的数据,而事务数据是主数据使用的数据。 数据对每个商业组织都很重要。数据种类繁多;主数据和事务数据是其中的两种。这两种数据类型都...

数据集成(data integration)和etl公司(etl)的区别
数据集成与ETL的主要区别在于,数据集成是将不同数据源中的数据进行组合,为用户提供统一的视图的过程,而ETL是在数据仓库环境中提取、转换和加载数据的过程。 数据集成是指将来自不同来源的数据组合成有意义和有价值...

数据冗余(data redundancy)和数据不一致(data inconsistency)的区别
数据冗余和数据不一致的主要区别在于,数据冗余是指当同一数据段存在于数据库的多个位置时发生的情况,而数据不一致是指当同一数据以不同格式存在于多个表中时发生的情况。 数据库是数据的集合。数据库管理系统(DBMS...

数据湖(data lake)和数据仓库(data warehouse)的区别
数据湖和数据仓库的主要区别在于,数据湖从物联网设备、网站、移动应用程序、社交媒体和企业应用程序获取非关系型和关系型数据,而数据仓库从事务系统、操作数据库和业务线应用程序获取数据。 数据湖是一个集中的存...

数据仓库(data warehouse)和数据集市(data mart)的区别
数据仓库和数据集市之间的主要区别在于,数据仓库是一个允许数据整合、分析和报告以做出业务决策的系统,而数据集市是数据仓库的子集,集中于组织的单个功能领域。 数据仓库是一个系统,它帮助分析数据、创建报表并...

属性数据(attribute data)和空间数据(spatial data)的区别
属性数据与空间数据的主要区别在于,属性数据描述地理要素的特征,空间数据描述地理要素的绝对位置和相对位置。 地理信息系统(GIS)是一种基于计算机的管理、分析和显示地理参考信息的工具或技术。地理信息系统(GIS...
0 篇文章





