今天使用tar文件格式的优点是什么?
 The tar archiving format is, in computing years, a veritable Methuselah yet it is still in heavy use today. What makes the tar format so useful long after its inception?
The tar archiving format is, in computing years, a veritable Methuselah yet it is still in heavy use today. What makes the tar format so useful long after its inception?
今天的问答环节是由SuperUser提供的,SuperUser是Stack Exchange的一个分支,是一个由社区驱动的问答网站分组。
问题
超级用户读者MarcusJ对tar格式很好奇,为什么这么多年后我们还在使用它:
I know that tar was made for tape archives back in the day, but today we have archive file formats that both aggregate files and perform compression within the same logical file format.
Questi***:
- Is there a performance penalty during the aggregation/compression/decompression stages for using tar encapsulated in gzip or bzip2, when compared to using a file format that does aggregation and compression in the same data structure? Assume the runtime of the compressor being compared is identical (e.g. gzip and Deflate are similar).
- Are there features of the tar file format that other file formats, such as .7z and .zip do not have?
- Since tar is such an old file format, and newer file formats exist today, why is tar (whether encapsulated in gzip, bzip2 or even the new xz) still so widely used today on GNU/Linux, Android, BSD, and other such UNIX operating systems, for file transfers, program source and binary downloads, and sometimes even as a package manager format?
这是一个非常合理的问题;在过去的三十年里,计算机世界发生了很大的变化,但我们仍然使用tar格式。怎么回事?
答案
超级用户贡献者Allquixotic对tar格式的寿命和功能提供了一些见解:
Part 1: Performance
Here is a comparison of two separate workflows and what they do.
You have a file on disk blah.tar.gz which is, say, 1 GB of gzip-compressed data which, when uncompressed, occupies 2 GB (so a compression ratio of 50%).
The way that you would create this, if you were to do archiving and compression separately, would be:
tar cf blah.tar files ...This would result in blah.tar which is a mere aggregation of the files ... in uncompressed form.
Then you would do
gzip blah.tarThis would read the contents of blah.tar from disk, compress them through the gzip compression algorithm, write the contents to blah.tar.gz, then unlink (delete) the file blah.tar.
Now, let’s decompress!
Way 1
You have blah.tar.gz, one way or another.
You decide to run:
gunzip blah.tar.gzThis will
- READ the 1GB compressed data contents of blah.tar.gz.
- PROCESS the compressed data through the gzip decompressor in memory.
- As the memory buffer fills up with “a block” worth of data, WRITE the uncompressed data into the fileblah.tar on disk and repeat until all the compressed data is read.
- Unlink (delete) the file blah.tar.gz.
Now, you have blah.tar on disk, which is uncompressed but contains one or more files within it, with very low data structure overhead. The file size is probably a couple bytes larger than the sum of all the file data would be.
You run:
tar xvf blah.tarThis will
- READ the 2GB of uncompressed data contents of blah.tar and the tar file format’s data structures, including information about file permissi***, file names, directories, etc.
- WRITE to disk the 2GB of data plus the metadata. This involves: translating the data structure / metadata information into creating new files and directories on disk as appropriate, or rewriting existing files and directories with new data contents.
The total data we READ from disk in this process was 1GB (for gunzip) + 2GB (for tar) = 3GB.
The total data we WROTE to disk in this process was 2GB (for gunzip) + 2GB (for tar) + a few bytes for metadata = about 4GB.
Way 2
You have blah.tar.gz, one way or another.
You decide to run:
tar xvzf blah.tar.gzThis will
- READ the 1GB compressed data contents of blah.tar.gz, a block at a time, into memory.
- PROCESS the compressed data through the gzip decompressor in memory.
- As the memory buffer fills up, it will pipe that data, in memory, through to the tar file format parser, which will read the information about metadata, etc. and the uncompressed file data.
- As the memory buffer fills up in the tar file parser, it will WRITE the uncompressed data to disk, by creating files and directories and filling them up with the uncompressed contents.
The total data we READ from disk in this process was 1GB of compressed data, period.
The total data we WROTE to disk in this process was 2GB of uncompressed data + a few bytes for metadata = about 2GB.
If you notice, the amount of disk I/O in Way 2 is identical to the disk I/O performed by, say, the Zip or7-Zip programs, adjusting for any differences in compression ratio.
And if compression ratio is your concern, use the Xz compressor to encapsulate tar, and you have LZMA2’ed TAR archive, which is just as efficient as the most advanced algorithm available to 7-Zip :-)
Part 2: Features
tar stores UNIX permissi*** within its file metadata, and is very well known and tested for successfully packing up a directory with all kinds of different permissi***, symbolic links, etc. There’s more than a few instances where one might need to glob a bunch of files into a single file or stream, but not necessarily compress it (although compression is useful and often used).
Part 3: Compatibility
Many tools are distributed in source or binary form as .tar.gz or .tar.bz2 because it is a “lowest common denominator” file format: much like most Windows users have access to .zip or .rar decompressors, most Linux installati***, even the most basic, will have access to at least tar and gunzip, no matter how old or pared down. Even Android firmwares have access to these tools.
New projects targeting audiences running modern distributi*** may very well distribute in a more modern format, such as .tar.xz (using the Xz (LZMA) compression format, which compresses better than gzip or bzip2), or .7z, which is similar to the Zip or Rar file formats in that it both compresses and specifies a layout for encapsulating multiple files into a single file.
You don’t see .7z used more often for the same reason that music isn’t sold from online download stores in brand new formats like Opus, or video in WebM. Compatibility with people running ancient or very basic systems.
有什么要补充的解释吗?在评论中发出声音。想从其他精通技术的Stack Exchange用户那里了解更多答案吗?在这里查看完整的讨论主题。
- 发表于 2021-04-11 23:20
- 阅读 ( 265 )
- 分类:互联网
你可能感兴趣的文章

使用简单的shell脚本修复html格式
...中,您会注意到有时会添加恼人的格式标记(如标记)。使用简单的shell脚本,您可以通过几个简单的命令自动清除那些垃圾HTML格式。 ...

这就是软件安装程序在windows、macos和linux上的工作方式
...软件经理/商店最终都会在幕后处理这些类型的包。对于今天的主要桌面平台——Windows、macOS和Linux——我们将了解这些软件包的组成,以及安装它们时会发生什么。 ...

如何在linux上安装软件:软件包格式说明
欢迎使用Linux。很可能你的发行版附带了大量的软件来涵盖基础知识。然而,无论它做了多么彻底的工作,你想安装更多。问题是,怎么做? ...

七大最佳在线rar提取器
... 此外,使用此转换文件所花费的时间比使用归档提取器将所有内容下载为ZIP所花费的时间要长。我们建议远离此网站。 ...

如何在linux中轻松地加密和解密文件和目录
... 使用openssl加密的基础知识 ...

如何监视linux命令的进度(使用pv和progress)
使用linuxpv和progress命令来跟踪命令的进度,而不是盲目飞行。这些实用程序将为您提供通常没有任何进度条的命令的进度条。你会看到一个估计的时间,直到完成,太。 如果你乘坐的是一架没有视频屏幕的飞机长途飞行,要知...
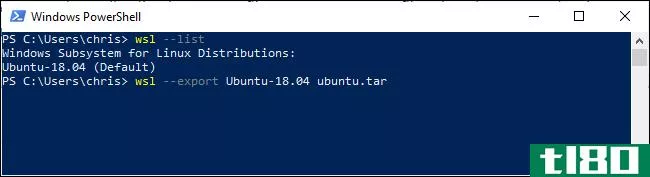
如何在Windows10上导出和导入linux系统
...的Windows10版本1903更新中添加的。如果尚未安装,则无法使用这些命令行选项。 您只需要为Windows wsl命令提供两个新选项:--export和--import。--export选项将Linux发行版的根文件系统导出为TAR文件。--import选项允许您将Linux发行版的根...

如何从文件中提取文件。焦油.gz或者。焦油bz2linux上的文件
Tar文件是压缩档案。在使用像Ubuntu这样的Linux发行版时,甚至在macOS上使用终端时,您会经常遇到它们。下面介绍如何提取或解压tar文件(也称为tarball)的内容。 这是什么。焦油.gz还有。焦油bz2什么意思? 文件有一个。焦油.gz...
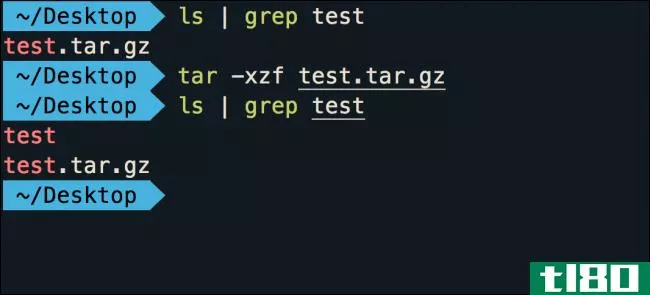
什么是焦油.gz文件,如何打开?
...油.gz文件简单的“tar文件” 如何打开tar文件? 如果您使用的是macOS或Linux,并且不介意使用终端,那么它只是一个命令(其中tarfile是您的文件名): tar -xzf tarfile 您还可以向命令添加一些标志,使其执行稍微不同的功能: -v:...

linux下如何使用tar命令压缩和提取文件
...成了压缩。它可以创建一个.tar存档,然后在一个命令中使用gzip或bzip2压缩对其进行压缩。这就是为什么生成的文件是一个。焦油.gz文件或。焦油bz2文件。 压缩整个目录或单个文件 在Linux上,使用以下命令压缩整个目录或单个...
0 篇文章