hadoop软件(hadoop)和天睿资讯(teradata)的区别
现在,技术比以往任何时候都在我们收集和使用数据的整个过程中发挥着关键作用。技术改变了数据的生产、处理和消费方式。随着大数据分析市场的迅速扩张,许多企业开始投资大数据技术来存储和分析这些海量数据。如今,市场上有许多大数据技术正在对处理大数据的新技术产生相当大的影响。其中一项一直处于大数据谈判中心的技术就是apachehadoop。Hadoop是大数据行业的大牌之一。Teradata是一个关系数据库管理系统,是一个领先的数据仓库解决方案,为分析提供数据管理解决方案。它用于在中央存储库中存储和处理大量结构化数据。下面是这两种技术的正面比较。
什么是hadoop软件(hadoop)?
Hadoop是大数据的核心。它是由Apache软件基金会开发的一个开源软件框架,用于存储和处理各种数据类型,使数据驱动的企业能够从所有数据中快速获得完整的价值。Hadoop是实现大数据战略的答案。Hadoop的最初创造者是Doug Cutting和Mike Cafarella。他们正在进行一个项目,创建一个名为“Nutch”的大型网络索引。他们看到了来自Google的MapReduce和GFS文件,发现它们对这个项目很有用。因此,他们最终将论文中的概念整合到项目中,最终形成了Hadoop项目的起源。道格给他的玩具大象取名为“Hadoop”,后来他把它用于他的开源项目。Hadoop廉价地存储数兆字节甚至数兆字节的数据,而不会丢失数据或中断数据分析。

什么是天睿资讯(teradata)?
Teradata是一个类似Oracle的关系数据库管理系统,由一家领先的同名软件公司开发。Teradata是全球领先的商业分析解决方案、数据和分析解决方案以及混合云产品和服务提供商。它在单个RDMS中提供关系数据库管理系统,RDMS充当中央存储库。它的RDBMS被认为是一个领先的数据仓库解决方案,运行世界上最大的商业数据库。Teradata为需要存储和分析千兆字节甚至万亿字节数据的组织和企业提供了决策支持功能。该公司成立于1979年,成立于加利福尼亚州布伦特伍德的一个**。Teradata这个名字象征着管理万亿字节数据的能力。这家公司实际上是由一群人创立的。
hadoop与teradata的区别
技术
–Hadoop是Apache软件基金会开发的一种大数据技术,用于在可扩展的商品硬件集群上存储和处理大数据应用程序。它是一个开放源代码平台,用于解决涉及大量数据的大数据挑战,这些数据过于多样化和快速变化,传统技术和基础设施无法有效应对。另一方面,Teradata是一个完全可扩展的关系数据库仓库,在单个RDBMS中实现,充当中央存储库。它是一个领先的数据仓库解决方案,运行世界上最大的商业数据库。
建筑学
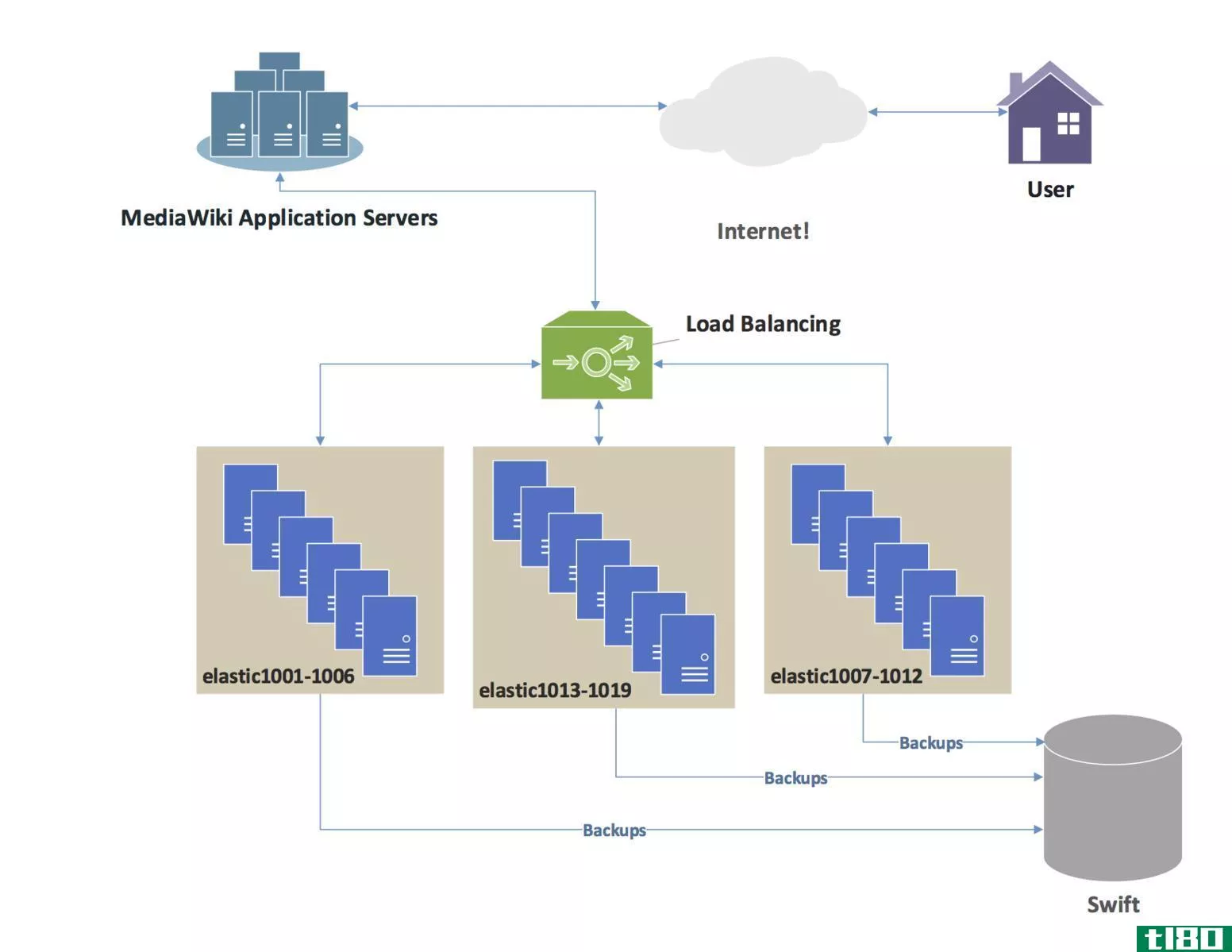
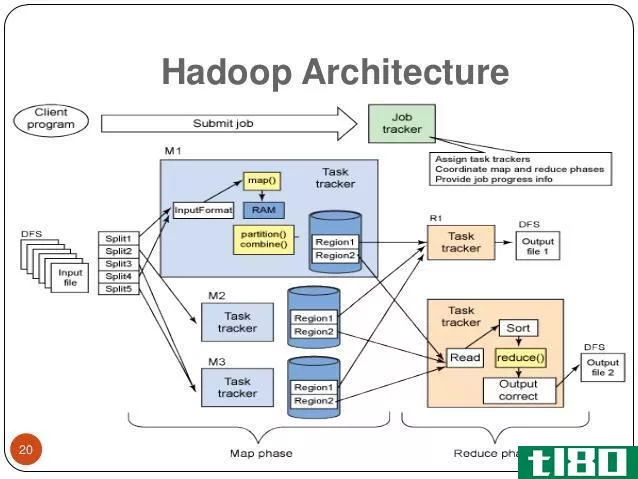
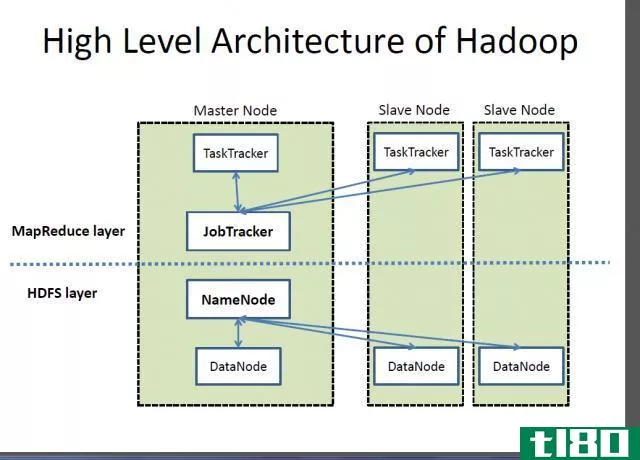
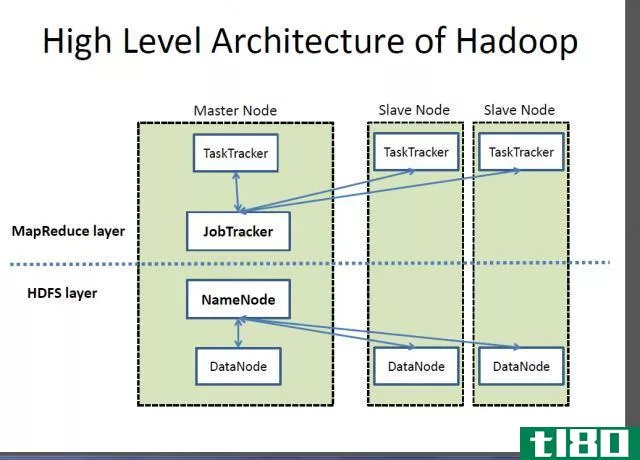
–Hadoop基于“主从架构”,集群由一个主节点组成,所有其他节点都是从节点。Hadoop体系结构基于三个子组件:HDFS(Hadoop分布式文件系统)、MapReduce和YARN(另一个资源协商器)。HDFS是Hadoop体系结构的存储部分;MapReduce是分发工作和收集结果的代理;然后分配系统中可用的资源。
Teradata是一种基于大规模并行处理(MPP)系统的无共享体系结构。Teradata DBMS在数据库系统工作负载的所有维度上都是线性的和可预测的可扩展的。它充当单个数据存储,可以接受来自多个客户端应用程序的大量并发请求。Teradata的主要组件是解析引擎、BYNET和AMPs(访问模块处理器)。
数据类型
–Hadoop用于存储和处理各种数据类型,使数据驱动的企业能够从所有数据中快速获得完整的价值。它可以使用多种开源工具处理任何类型的数据,而不管数据类型是结构化半结构化数据还是非结构化数据。Hadoop处理非结构化数据的卓越能力是无与伦比的。另一方面,Teradata是一种关系数据仓库解决方案,最适合用于存储和处理大量结构化表格格式的数据。它不适合处理半结构化或非结构化数据。
hadoop与teradata:比较图

总结 - hadoop的应用(of hadoop) vs. 天睿资讯(teradata)
Hadoop以低廉的价格存储数TB甚至数PB的数据,而不会丢失数据。它可以使用多种开源工具处理任何类型的数据。另一方面,Teradata是一种完全可扩展的关系数据库管理解决方案,用于在中央存储库中存储和处理大量结构化数据。Hadoop基于“主从架构”,其中集群由一个主节点组成,所有其他节点都是从节点,而Teradata是基于大规模并行处理(MPP)系统的无共享架构。
- 发表于 2021-06-26 12:41
- 阅读 ( 496 )
- 分类:IT
你可能感兴趣的文章

关系数据库管理系统(rdbms)和hadoop公司(hadoop)的区别
RDBMS和Hadoop的关键区别在于RDBMS存储结构化数据,而Hadoop存储结构化、半结构化和非结构化数据。 关系数据库管理系统是一个基于关系模型的数据库管理系统。Hadoop是一种用于在商品硬件集群上存储数据和运行应用程序的软件...

大数据(big data)和hadoop公司(hadoop)的区别
关键区别——大数据与hadoop 数据在世界各地广泛收集。这种大量的数据称为大数据或大数据,常规存储设备无法处理。Hadoop软件框架是Apache软件基金会的一个开源框架,可以用来解决这个问题。大数据与Hadoop的关键区别在于...

java程序员的职业选择
... Hadoop是第一个将大数据带给大众的平台 近年来取得进展的星火 Pig是一种用于编写大数据处理作业的语言 MapReduce是处理大数据的...

5门课程对数据科学的温和介绍
...知识,然后再决定向大数据处理工具(如R编程、Python、Hadoop、Spar、Panda、Dremel等)迈进一步。 ...

网络巨人是如何存储海量数据的
...一致性检查,不过在数据写入的执行方式上要严格得多。Hadoop最初是由雅虎的工程师开发的,它可以****,并分享GFS的许多好处,不过它可以在各种平台上工作,甚至可以通过FUSE安装在普通PC上。
hadoop软件(hadoop)和火花(spark)的区别
...需要更复杂的解决方案,以使用户更容易访问信息。apachehadoop就是这样一种用于存储和处理大数据的解决方案,它与apachespark等许多其他大数据工具一起使用。但是哪一个是数据处理和分析的正确框架呢?Hadoop还是Spark?让我们...
hadoop软件(hadoop)和数据库(mongodb)的区别
...据解决方案。在众多技术中,在存储和处理大数据方面,Hadoop和MongoDB是两种流行的选择。虽然两者在基本上是相似的,但他们的方法是非常不同的。让我们看看。 什么是数据库(mongodb)? MongoDB是一个开源文档数据库,它已经...
数据库(hbase)和蜂巢(hive)的区别
HBase和Hive都是基于Hadoop的数据仓库结构,在存储和查询数据的方式上有很大的不同。通过传统的数据库管理工具来管理和处理大量基于web的数据变得越来越困难。这就是HBase的用武之地。HBase是处理大量数据的首选。例如,如果...
hadoop软件(hadoop)和sql语句(sql)的区别
...设备的数量不断增加,数据量激增。大数据正是开源框架Hadoop的用武之地。Hadoop提供了一个用于存储和检索大量数据以进行处理和分析的框架。但是Hadoop与其他数据库管理系统(如sqlserver)有什么不同呢?我们将重点介绍SQL和Had...
hadoop软件(hadoop)和卡桑德拉(cassandra)的区别
...的海量数据,存储和分析这些海量数据的能力已经提高。Hadoop是设计用来处理如此大量数据(通常称为大数据)的复杂工具之一。Cassandra是另一个易于部署和管理的高度可扩展数据库。但Hadoop和Cassandra哪个是最好的选择? 什...
0 篇文章