生物信息学中同源性与相似性的关键区别在于同源性是指两个序列的共同进化祖先的陈述,而相似性是指两个序列之间的相似程度。
生物信息学是一门结合生物学、信息工程、计算机科学、数学和统计学来分析和解释生物数据的科学领域。同源性和相似性是我们在生物信息学领域使用的两个术语。我们可以很容易地将相似性计算为给定排列长度上相似残基的百分比。然而,我们不能计算同源性,因为它可能是真或假,通常取决于所用的假设。
目录
1. 概述和主要区别
2. 什么是生物信息学中的同源性
3. 生物信息学中的相似性是什么
4. 生物信息学中同源性与相似性的相似性
5. 并列比较-表格式生物信息学中的同源性与相似性
6. 摘要
什么是生物信息学中的同源性(homology in bioinformatics)?
生物信息学中的同源性是指DNA、RNA和蛋白质序列之间的生物同源性,这些序列是根据生命进化树中的共同祖先属性定义的。换句话说,它是两个序列的共同进化祖先。发生这种情况的原因可能是由于物种形成事件(正交记录)、水平基因转移事件(异种)或复制事件(副记录)。
和生物信息学中的相似性(similarity in bioinformatics)的区别1")
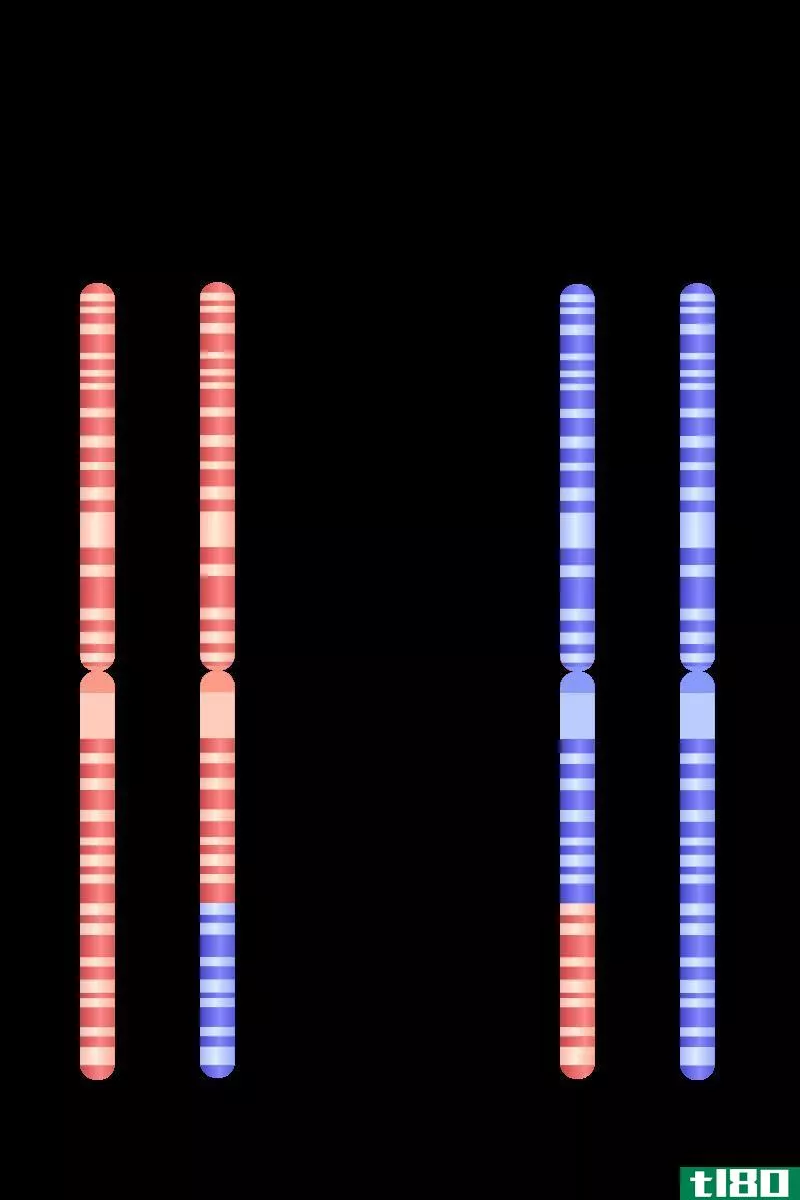
图01:多序列比对
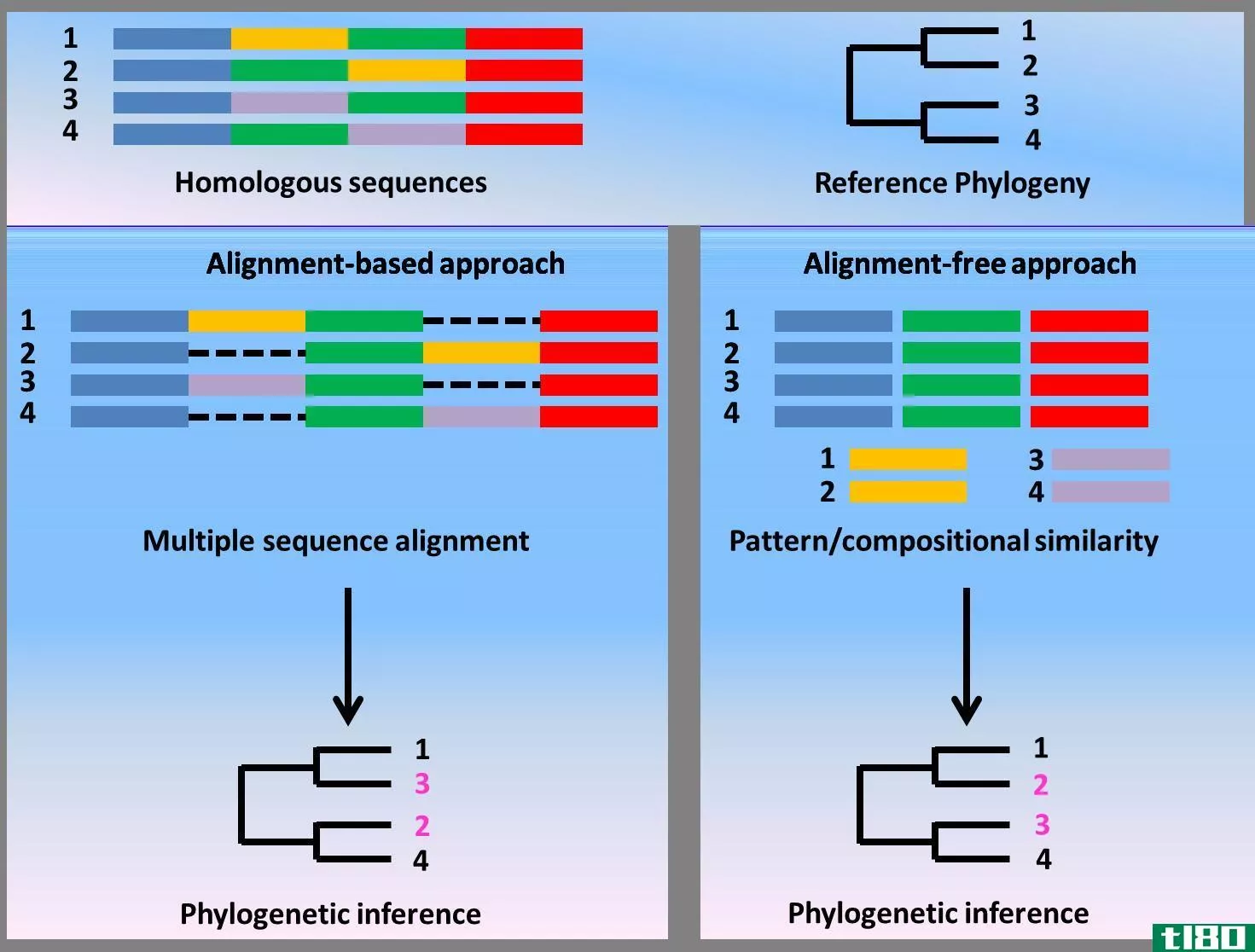
利用DNA、RNA或蛋白质的氨基酸或核苷酸序列的相似性,可以推断它们之间的同源性。显著的相似性可以作为一个很强的证据属性来推断两个序列与一个共同的祖先序列有着进化上的变化。多个序列的比对表明每个序列具有同源性的区域。
什么是生物信息学中的相似性(similarity in bioinformatics)?
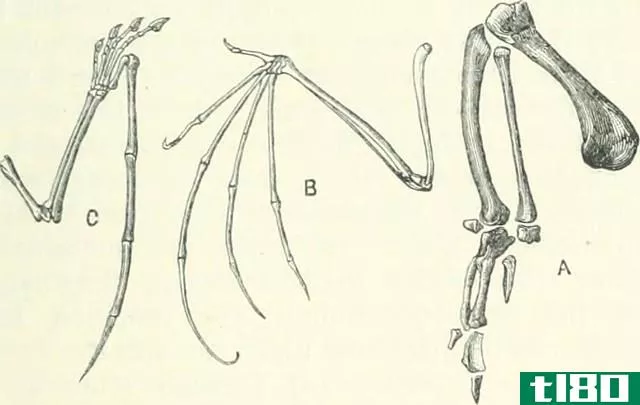
在生物信息学中,相似性评估两个蛋白质或核苷酸序列之间的相似性。这个过程有两个主要步骤。初始步骤是成对比对,这有助于使用BLAST、FastA和LALIGN等算法在两个序列(包括间隙)之间找到最佳对齐。成对比对后,需要从每对比对中获得两个定量参数。它们是同一性和相似性。在BLAST中,搜索的相似性被称为积极因素。
和生物信息学中的相似性(similarity in bioinformatics)的区别2")
图02:成对对齐
当一个氨基酸突变成类似的残基,同时保持其理化性质时,就会发生保守突变。例如,如果精氨酸突变为带有+1正电荷的赖氨酸,这是可以接受的,因为这两种氨基酸性质相似,不会改变翻译的蛋白质。因此,相似性的测量取决于两个氨基酸残基之间的相互关系。
同源性(homology)和生物信息学中的相似性(similarity in bioinformatics)的共同点
- 同源性和相似性是我们在生物信息学中遇到的两个术语。
- 此外,这两个术语都指序列的分子分析。
同源性(homology)和生物信息学中的相似性(similarity in bioinformatics)的区别
同源性是指两个序列的共同进化祖先,而相似性是指两个序列之间的相似程度。所以,这就是生物信息学中同源性和相似性的关键区别。此外,同源性不能计算,因为它可能是真的或假的,通常取决于假设,而相似性可以很容易地计算为在给定的比对长度上的相似残基的百分比。因此,这是生物信息学中同源性和相似性的一个显著区别。
下面的信息图列出了生物信息学中同源性和相似性之间的区别。
和生物信息学中的相似性(similarity in bioinformatics)的区别3")
总结 - 同源性(homology) vs. 生物信息学中的相似性(similarity in bioinformatics)
简言之,生物信息学中同源性和相似性的关键区别在于它们的定义。同源性是两个序列共同的进化祖先的陈述,而相似性是两个序列之间的相似性。同源性是由正射测井曲线、平行测井曲线和氙测井曲线引起的。在推导相似性时,可以使用FastA、BLAST和LALIGN等算法。同源性不能用计算来表示,但是相似性可以用在给定的排列长度上相似残基的百分比来表示。因此,这是生物信息学中同源性和相似性的区别的总结。
引用
1.“同系物。”同源物-生物信息学.Org维基,在这里可以找到。“同一性和相似性——一种定量的测量方法。”同一性和相似性——一种定量的测量方法,可以在这里找到。
2“同一性和相似性——一种定量的衡量方法。”同一性和相似性——一种定量的衡量方法,