总体与样本标准差
在统计学中,用几个指标来描述一个数据集,它对应于它的中心趋势、分散性和偏斜性。标准差是数据集中心数据分散的最常用度量之一。
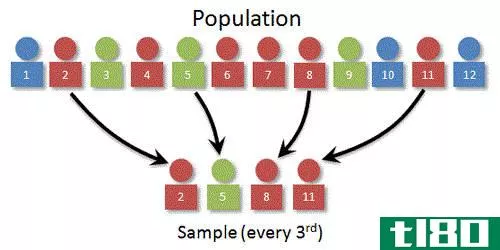
由于实际困难,当一个假设被检验时,不可能利用全体人口的数据。因此,我们使用样本中的数据值来推断总体。在这种情况下,这些被称为估计量,因为它们估计总体参数值。
在推理中使用无偏估计量是非常重要的。如果一个估计量的期望值等于总体参数,则称该估计量是无偏的。例如,我们使用样本平均值作为总体平均值的无偏估计量。(在数学上,可以证明样本平均值的期望值等于总体平均值)。样本总体的标准差估计也是无偏的。
什么是总体标准差?
当所有人口的数据都可以考虑在内时(例如在人口普查的情况下),就可以计算出人口的标准差。为了计算总体的标准差,首先计算数据值与总体平均值的偏差。偏差的均方根(二次平均值)称为总体标准差。
在一个10人的班级里,学生的资料可以很容易地收集。如果一个假设在这群学生中得到检验,那么就没有必要使用样本值。例如,10名学生的体重(公斤)被测量为70、62、65、72、80、70、63、72、77和79。十个人的平均体重(公斤)是(70+62+65+72+80+70+63+72+77+79)/10,即71(公斤)。这是人口平均数。
现在要计算总体标准差,我们计算平均值的偏差。与平均值的偏差分别为(70-71)=-1,(62-71)=-9,(65-71)=-6,(72-71)=1,(80-71)=9,(70-71)=-1,(63-71)=-8,(72-71)=1,(77-71)=6和(79-71)=8。偏差平方和为(-1)2+(-9)2+(-6)2+12+92+(-1)2+(-8)2+12+62+82=366。总体标准差为√(366/10)=6.05(千克)。71是全班学生的准确平均体重,6.05是体重与71的准确标准差。
什么是样品标准差?
当样本(大小为n)的数据用于估计总体参数时,计算样本标准差。首先计算数据值与样本均值的偏差。由于使用样本平均值代替总体平均值(未知),所以采用二次平均值是不合适的。为了补偿样本平均值的使用,偏差平方和除以(n-1)而不是n。样本标准差是其平方根。在数学符号中,S={{(2)(n-1)},其中S是样本标准偏差,即样本均值和席席是数据点。
现在假设,在前面的例子中,人口是全校的学生。那么,这个类将只是一个样本。如果在估算中使用该样本,则样本标准差将为√(366/9)=6.38(千克),因为366除以9而不是10(样本量)。要观察的事实是,这不能保证是准确的总体标准偏差值。这只是一个估计。
| 总体标准差和样本标准差有什么区别?•总体标准差是用于测量离中心的离差的精确参数值,而样本标准差是其无偏估计量。•人口标准差是在人口中每个个体的所有数据已知时计算的。另外,样本标准差是由标准值α={{(2)/n }给出的,即人口平均数和n是种群大小,但样本标准偏差由S={{席(2))/(n-1)}给出,其中席是样本均值,n是样本大小。 |